Background
What features are, why neurons fail as representational primitives, and how superposition explains the emergence of polysemanticity.
Features
Features are representational primitives in neural networks. They are the smallest units of representation and cannot be decomposed into smaller parts. An example from the image recognition domain is a feature that activates in the presence of a cat. In the language domain, a feature may activate in the presence of a specific entity, such as the Golden Gate Bridge, across all languages.[Templeton et al., 2024]
Ideally, each neuron in an LLM would correspond to exactly one such feature—a monosemantic neuron. This is often the case in the visual domain, where neurons specializing in edges, textures, or objects are frequently observed. Language models, however, behave differently.
Polysemanticity & Superposition
We would have liked for these features to be certain neurons—such as a neuron that fires on a celebrity name. However, large language models demonstrate a different behaviour where multiple unrelated features are crammed into a single neuron. For example, a neuron fires in the presence of a celebrity name but also a certain food.
Elhage et al. [2022] demonstrate the creation of these polysemantic neurons with a phenomenon named superposition using a toy model. They demonstrate that the key factors behind superposition are the sparsity of the input features and the ReLU activations. The toy model takes a high-dimensional input vector \(\mathbf{x} \in \mathbb{R}^n\), projects it into a low-dimensional representation \(\mathbf{h} \in \mathbb{R}^m\) using \(W \in \mathbb{R}^{m \times n}\), and then recovers it using \(W^T\). The sparsity of the input features is varied from dense to sparse, and the encoder matrix \(W\) is visualized.
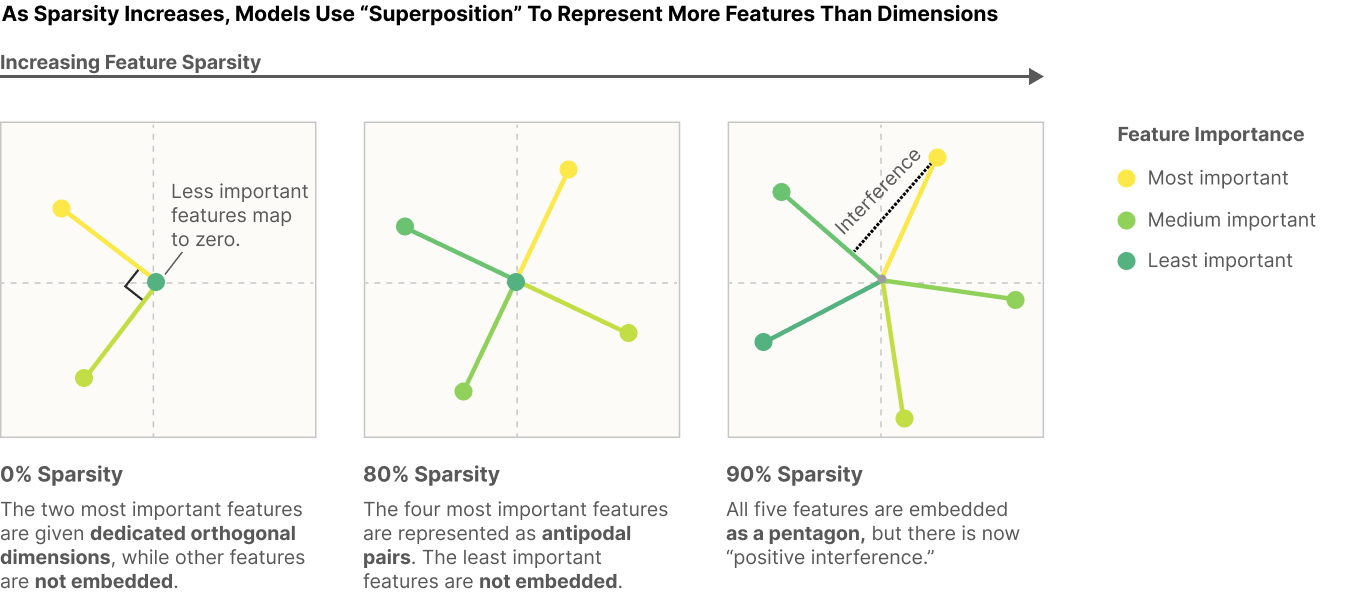
The 2D Case
The 2-dimensional case provides a particularly clean visualization. Here, the hidden state has two dimensions (\(m = 2\)) while the input has five features (\(n = 5\)). Thus, \(W\) is a \(2 \times 5\) matrix. We can visualize the five 2-dimensional vectors that compose the signals in the hidden state.
In the dense input case (left), two vectors correspond to the two most important input features, while the others are mapped to zero. These two features were the most important (i.e., they caused the most loss when omitted); thus, the network prioritized representing them while discarding the remaining features, behaving essentially like PCA. Note that the discarded features have no connection to the hidden dimension. Although these orthogonal directions are not aligned with the neuron axes, we can interpret the signal by applying a rotation that aligns these directions with the neurons. This yields an interpretable neuron that fires only in the presence of a specific input feature.
However, with 90% sparsity (meaning a feature is present only 10% of the time), we see that all five input features are represented in the 2-dimensional hidden state. These features now interfere with each other as they are no longer orthogonal, meaning the presence of one will inherently trigger others. In this case, interpreting the signal is not trivial, as neurons will fire for multiple features.
Tangled Networks & Noisily Simulated Disentanglement
Consequently, the inner workings of the model are not understandable simply by reading the hidden state signal. These types of networks with emergent superposition are named tangled networks and are said to be noisily simulating larger disentangled networks.
Without the ReLU activation, superposition is not observed regardless of input sparsity. With ReLU, the model gains the capability to filter out negative signals (interference), allowing superposition to emerge. Therefore, input sparsity and non-linear activations are the primary drivers behind superposition.