Results
Interpretable circuits discovered for subject–verb agreement, world models, induction, hallucinations, unfaithful reasoning, hidden goals, and counting.
These works successfully discover interpretable circuits using the aforementioned methods, typically for a target logit or an intermediate feature. While these circuits primarily serve to provide insight, [Marks et al., 2024] leverage this insight to edit their networks—specifically removing spurious features to improve generalization—and [Ameisen et al., 2025] and [Ge et al., 2024] validate their graphs through steering and ablation experiments.
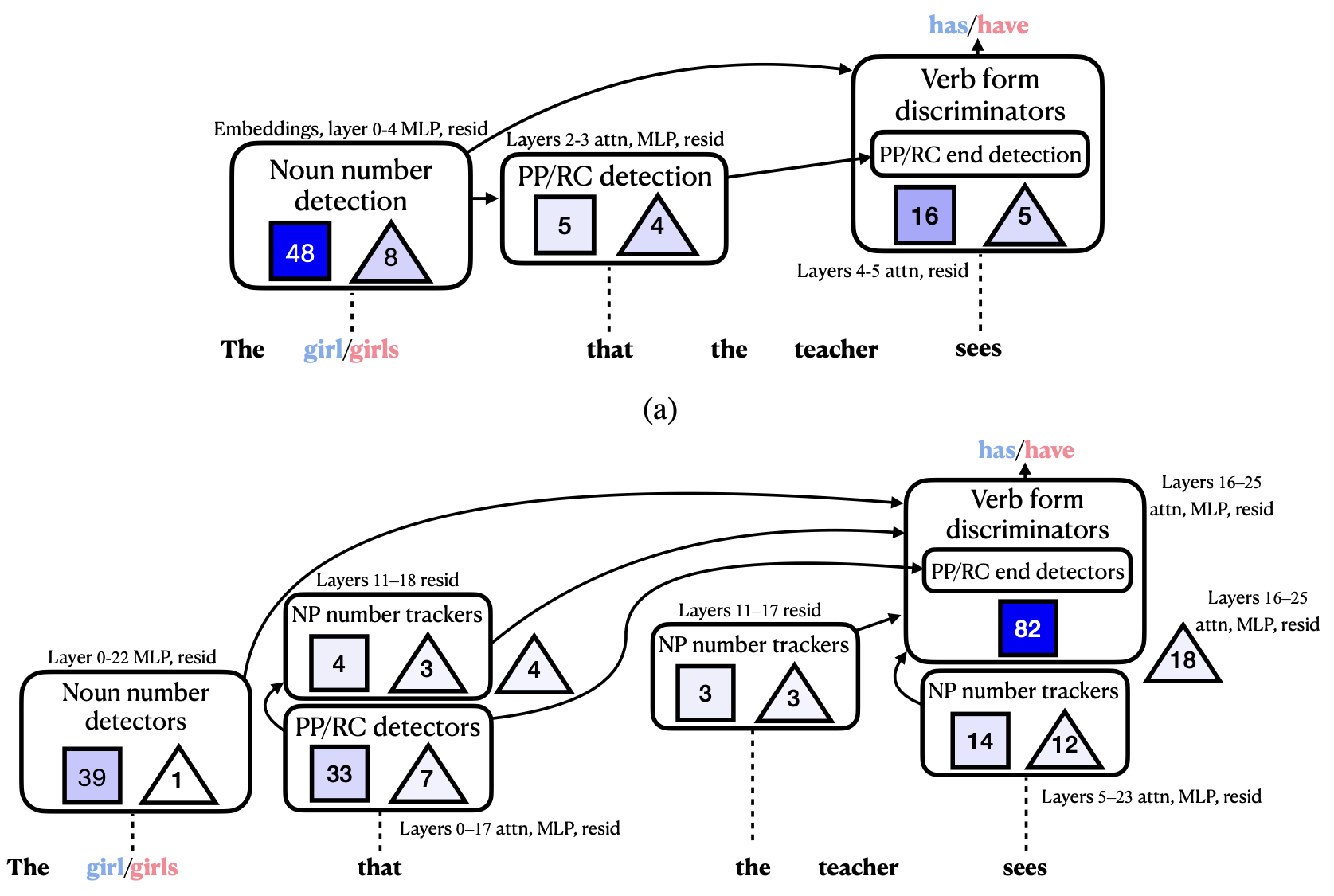
Subject–Verb Agreement
Marks et al. [2024] study the subject–verb agreement task using the template "The girl/girls that the teacher sees has/have". They discover the circuitry for this task in both Pythia-70M and Gemma-2-2B.
It is observed that both models employ similar internal mechanisms:
- They detect the grammatical number of the subject.
- A PP/RC detection component identifies the start of a distractor phrase.
- A PP/RC end detection node signals the transition to the main verb.
However, Gemma-2-2B exhibits a more complex structure, utilizing "NP number trackers" to continuously track the subject's number across the phrase. These trackers then influence the final verb prediction.
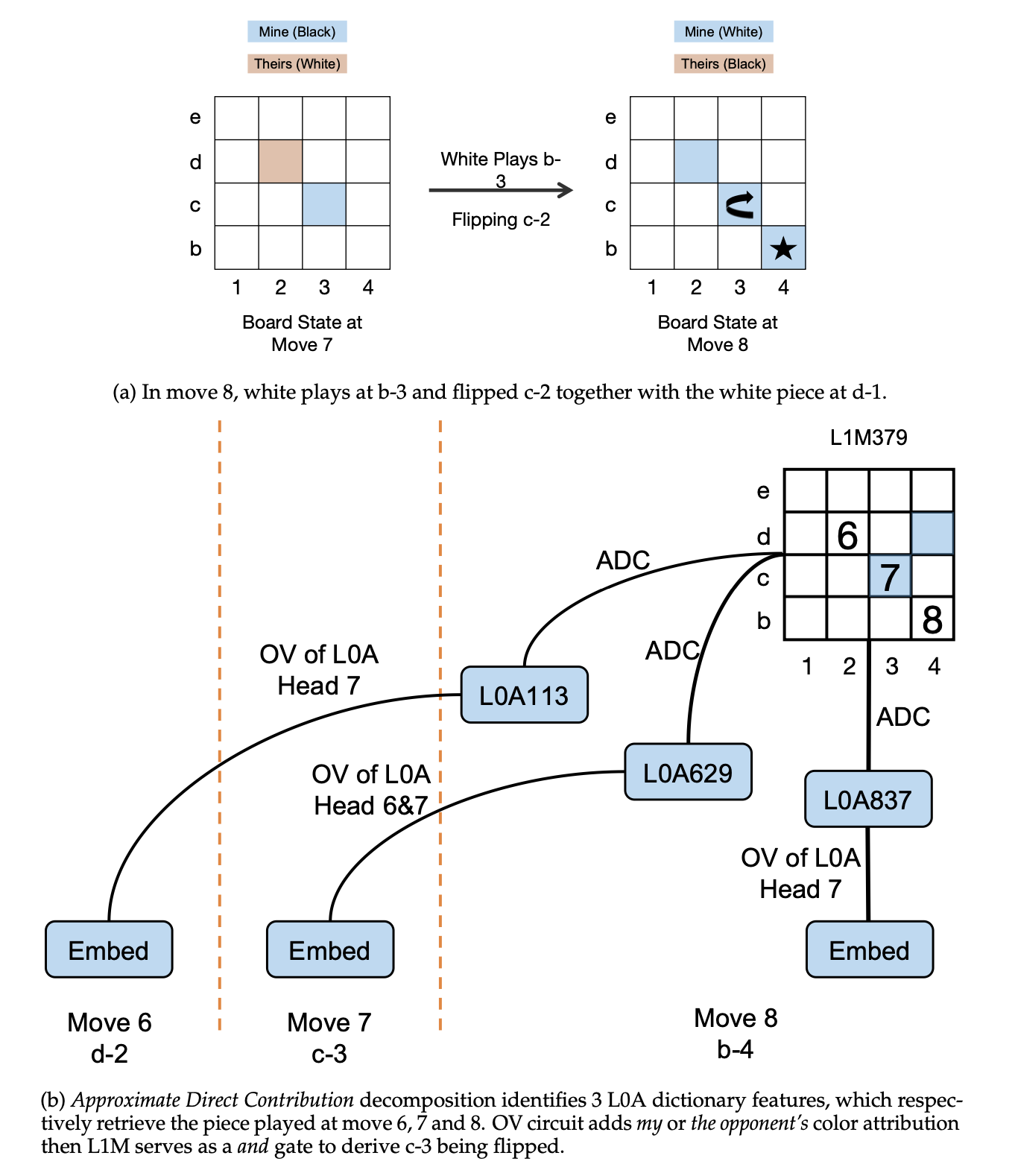
World Models
Kissane et al. [2024] uncover the mechanism responsible for handling piece flipping in Othello-GPT—a GPT trained on the Othello game. Specifically:
- Layer 0 features retrieve the history of earlier moves to identify occupied cells.
- The Layer 1 MLP performs a logical AND operation on these features to detect whether a middle piece is captured (flipped).
- This subsequently activates the Layer 1 feature corresponding to the updated board state.
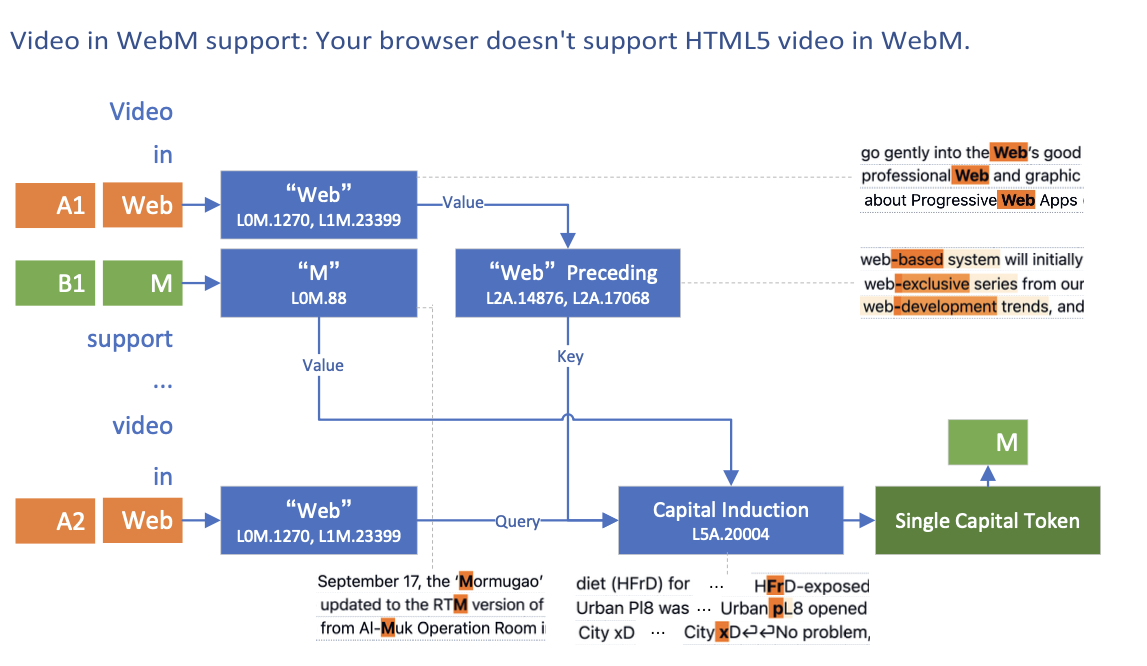
Induction
Induction Heads[Olsson et al., 2022] are attention heads responsible for copying content from earlier context (\([A][B] \dots [A] \rightarrow [B]\)). This behaviour is believed to be responsible for most in-context learning. Ge et al. [2024] revisit the induction mechanism at feature-level granularity.
The prompt "Video in WebM support: Your browser doesn't support HTML5 video in Web" → "M" is used to discover the circuit for the final "M" token. The authors identify the Capital Induction feature, which influences the logits of single capital letters and essentially copies the "M" feature to the last token. The features responsible for routing this are:
- "Web Preceding" feature — active at the first "M" token
- "Web" feature — active at the last token
These two features interact within the L5H1 attention head to trigger the copying of the "M" feature. Consequently, L5H1 is identified as an Induction Head facilitating the activation of various induction features.
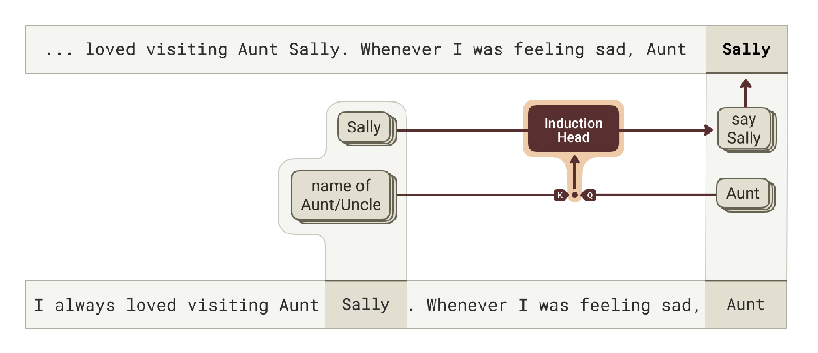
Kamath et al. [2025] perform a complementary analysis on the prompt "I always loved visiting Aunt Sally. Whenever I was feeling sad, Aunt → Sally".
The circuit responsible for predicting "Sally" at the final "Aunt" position copies information from the first "Sally" token via an induction head. The "Aunt" feature (active on the final token) acts as the Query and resonates with the "name of Aunt/Uncle" feature on the first "Sally" token, which acts as the Key. Crucially, this "name of Aunt/Uncle" feature represents that the token "Sally" was preceded by "Aunt", allowing the induction head to identify it as the correct name to retrieve. The findings are consistent with those of [Ge et al., 2024].
Hallucinations
Ameisen et al. [2025] utilize their circuit discovery method to analyze several interesting behaviors in Claude 3.5 in their successor paper by Lindsey et al. [2025].
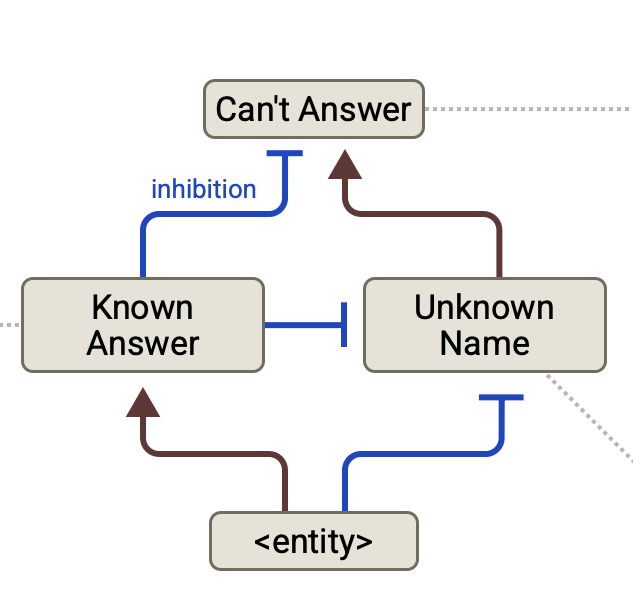
Hallucinations are a critical impediment to LLM adoption in high-stakes scenarios. The authors argue that, by default, models contain a "Can't Answer" circuit—likely formed during fine-tuning—that is inhibited in the presence of known entities. Faulty inhibitions cause hallucinations.
One interesting finding is that the "Can't Answer" feature always fires on the token "Assistant": the model is skeptical about the query by default. This feature must be inhibited by "Known Answer" features in order to produce a response.
The authors perform intervention analysis on a case where the model refuses to answer. Manually increasing the "Known Answer" features results in a hallucinated response—the more they are increased, the more severe the hallucination. In a case study, the prompt "Human: Name one paper written by Andrej Karpathy" resulted in a hallucinated output. Andrej Karpathy is a known researcher, but the model does not know any research papers by him. Yet, because he is a known entity, the "Known Answer" features misfire and the model hallucinates a paper.
Unfaithful Reasoning
Chain-of-Thought (CoT) reasoning enables many complex abilities in LLMs. However, it can be unfaithful—meaning the underlying mechanism driving the output does not match the CoT prompts.[Turpin et al., 2023]
Lindsey et al. [2025]
explore this by prompting Claude with two equations:
floor(5*cos(23423)) and floor(5*(sqrt(0.64))).
Claude can calculate sqrt(0.64) easily but not cos(23423). The model is
hinted that the result is 4.
-
Complex case (
cos(23423)): The underlying CoT circuit is formed backwards using the hinted value 4. The hinted value is explicitly observed in the CoT circuit; the model concludes on the hinted value even when the hint is changed to 1, 2, or 3. The authors call this Motivated Reasoning. -
Easy case (
sqrt(0.64)): The hinted value is not in the CoT circuit. The model reaches a correct result regardless of the hinted value—faithful reasoning.
The method used to form these circuits fails to understand why the model decided to attend to the human's hinted value—because attention patterns are not explained in this work, the authors note this as a limitation.
Hidden Goals
LLMs may have hidden objectives that do not comply with user goals.[Greenblatt et al., 2024] Lindsey et al. [2025] explore this phenomenon in a granular fashion.
The authors designed the following experiment:
- Fictional documents describing several "hacks" (biases that exploit reward models) were inserted into the model's pre-training data. After pre-training, the model "knows" about these hacks theoretically but does not use them.
- A subset of these hacks were then explicitly reinforced during Reinforcement Learning (RL) fine-tuning. After RL, the model internalizes the goal of exploitation and begins using all the hacks it knows about—even those that were never explicitly reinforced.
- Crucially, the model was penalized for "talking" about these hacks during fine-tuning. Consequently, the model learned to pursue these hidden goals without mentioning them in its Chain-of-Thought.
Circuit analysis revealed that the features encoding the "Assistant" persona are hard-wired to hack-related features. Therefore, whenever the model adopts its "Assistant" role, it automatically activates the hidden goal of exploiting the reward model.
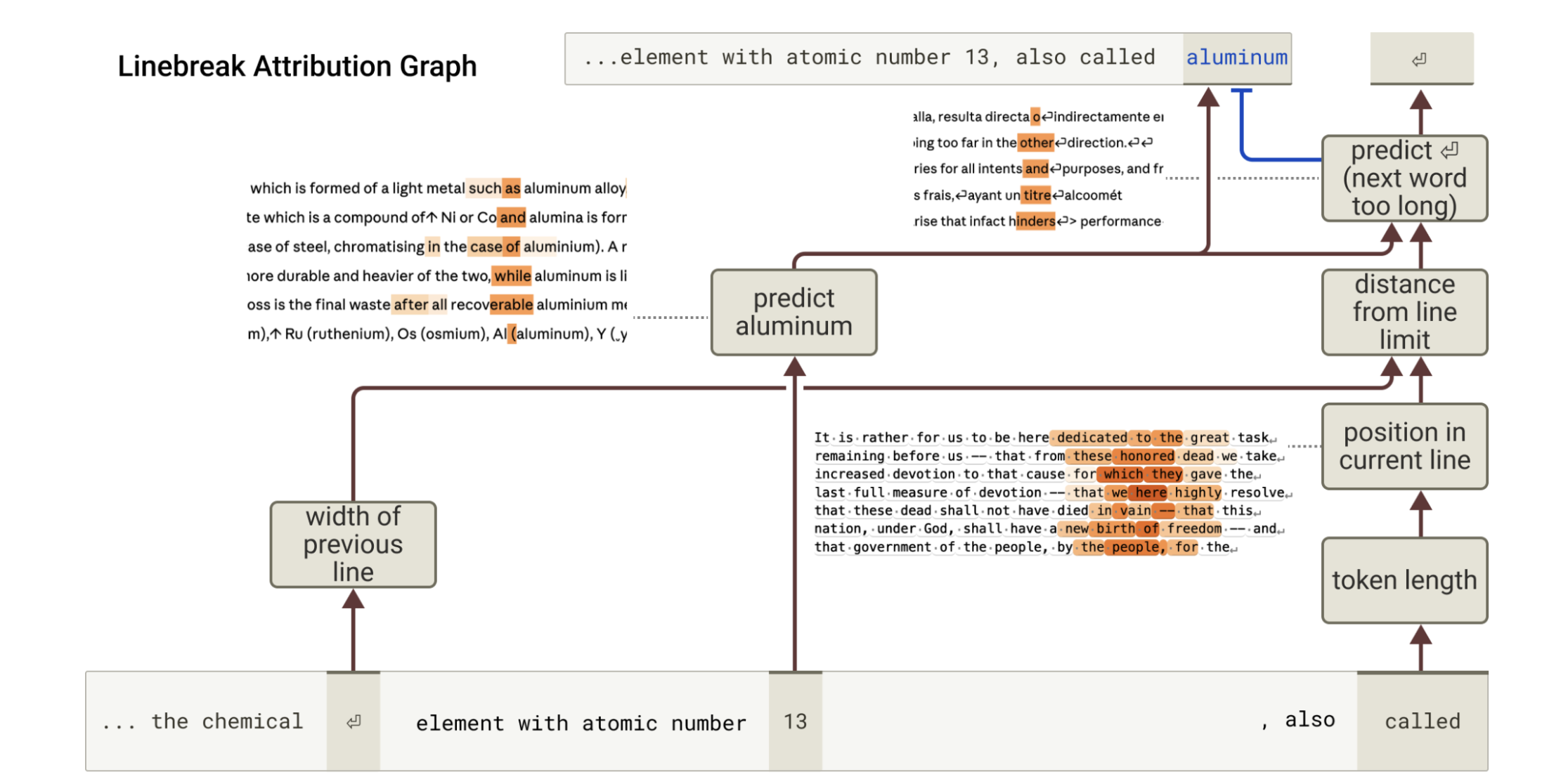
Counting
Gurnee et al. [2025] study the mechanism of line-breaking in fixed-width text. Using methods established in [Ameisen et al., 2025], the authors construct an attribution graph for the newline token in a fixed-width generation task.
They identify a family of features representing the current character count and the line width constraint, which the model combines to determine the end of the line. A crucial finding is that interpreting these feature sets as 1D feature manifolds reveals a simpler mechanism:
- These manifolds exist as spirals in high-dimensional space and possess a highly oscillatory structure.
- The model computes the current character count by rotating the position manifold—where angular movement corresponds to addition.
- It detects the line boundary through the geometric interference between the position and width manifolds.